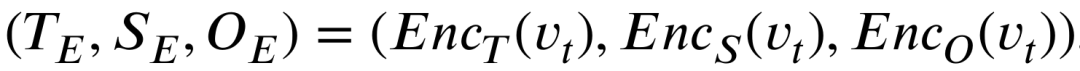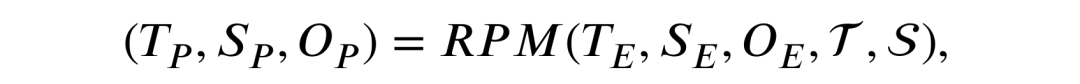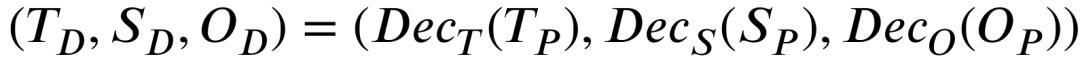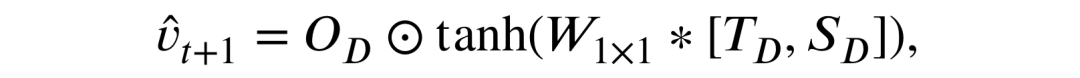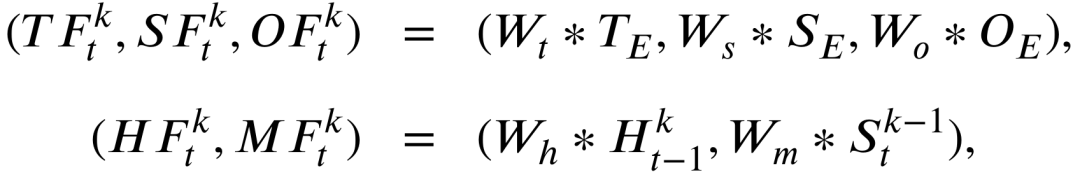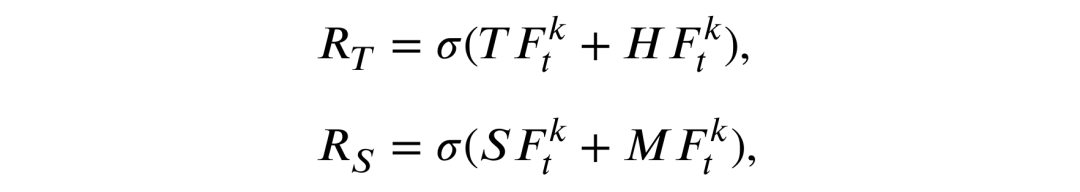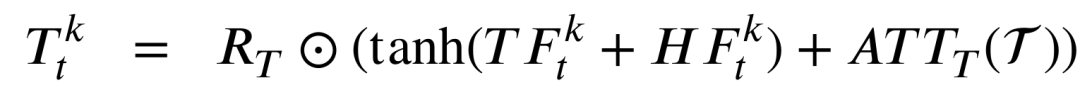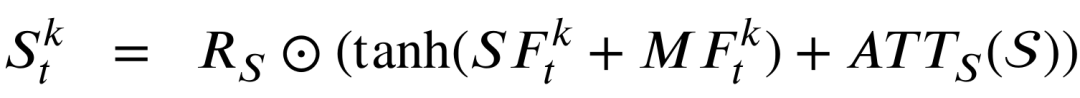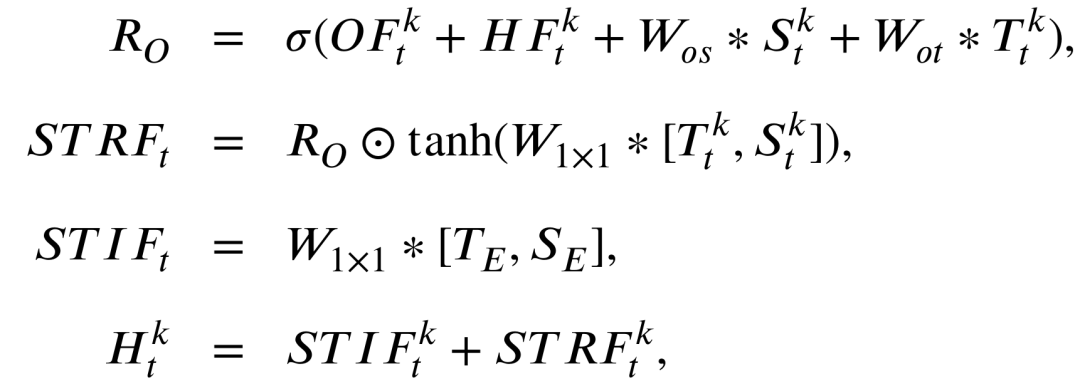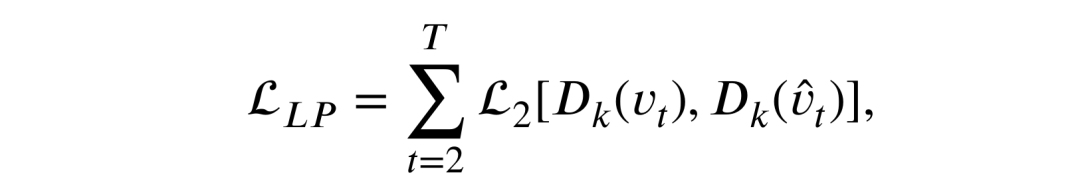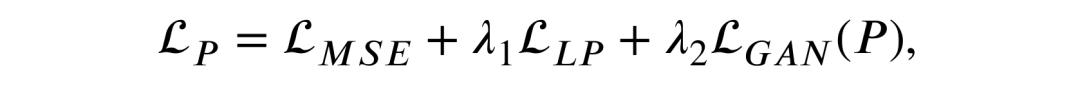不同方法在SJTU4K数据集上的预测样例,4帧预测1帧
不同方法在SJTU4K数据集上的预测样例,4帧预测1帧
本文是CVPR 2022入选论文《STRPM: A Spatiotemporal Residual Predictive Model for High-Resolution Video Prediction》的解读。
该论文由北京大学马思伟课题组完成,针对视频预测领域高分辨率视频预测的难点问题,提出了一个轻量级的时空差分预测模型。
实验证明,本文所提出的方法在预测高分辨视频时优势明显,用较少的计算复杂度实现了较高的模型性能。
论文地址:static/file/2203.16084.pdf
引言
高分辨率视频预测问题一直以来都是视频预测领域的难点问题。和低分辨率视频相比,高分辨率视频的每一帧包含着极为复杂的空间特征,并且帧与帧之间的运动信息也通常会涉及到多个运动物体,模式更为复杂。
直观上来说,高分辨率视频的时空结构具有明显的高维特性。为节省计算量,现有的视频预测算法在时空预测之前通常会把高维数据压缩到低维特征,但是这种特征提取的过程会把高分辨率视频中很多有用的时空信息进行丢弃,
导致最后重建的视频帧的先验信息不足,无法重建出比较满意的结果。
高分辨率视频预测的关键在于是否可以保留足够多的时空信息用于高维数据空间重建。一个比较简单的保留信息的方式是提高编码特征的维度,但是这会极大增加预测模型的计算量,影响模型的效率。
为解决这个问题,本文提出了一个时空残差预测模型(Spatiotemporal Residual Predictive Model, STRPM),从两方面对高分辨视频的时空内容进行高效保护:
1.在特征提取过程中,本节使用多个编码器在时域和空域上对输入的高维视频帧分别进行独立的特征提取操作,在送入到预测单元之前,尽可能避免时空信息之间的相互扰乱,尽可能在特征提取过程中保护高维空域信息。
同时和其他方法相比,所提出的方法提取的特征维度较低,虽然使用了多个编码器,但是总体的计算量仍然优于传统方法,提取到的低维度时空特征随后会被送入到预测单元之中。由于高分辨率视频帧背景内容的运动信息可以忽略不计,
因此我们设计了一种新型的轻量级残差预测单元(Residual Predictive Memory, RPM)来着重预测帧间的残差信息,冗余的背景信息则直接通过残差连接进行重建,这样做的目的是集中所有的计算量和参数建模最为重要的帧间残差信息,
在时空预测过程中极大程度地保护高分辨视频的高维时域信息。同时由于 RPM 的不同模块将会收到经过不同编码器编码的低维度特征,因此 RPM 可以对不同的编码器进行监督,使它们可以真正地提取到时域和空域上的有用特征。
2.在数据重建过程中,本节所提出的方法选用基于生成对抗网络(GAN)的概率性预测方法。虽然本文采用的特征提取机制和时空预测机制可以极大程度上为高分辨率视频在时空域上进行信息保护,但是仍然有或多或少的信息在特征提取过程中会被丢弃,
因此为进一步提高重建帧地视觉质量,本节借助于GAN强大的数据生成能力对高分辨视频的纹理细节进行动态补全。由于 GAN 引入的判别性损失会增大生成帧和真实帧之间的客观损失,如 MSE, MAE 等,为了缩小主观质量和客观质量之间的差距,
本节将 GAN 中判别器中间层的特征作为每一帧视频的感知表征信息,通过优化生成帧和真实帧之间感知表征信息的差距,在保证视频帧内容真实性的基础上尽可能提高客观性能指标。
方法简介
本文所提出的时空残差预测模型的基本框架如图1所示。
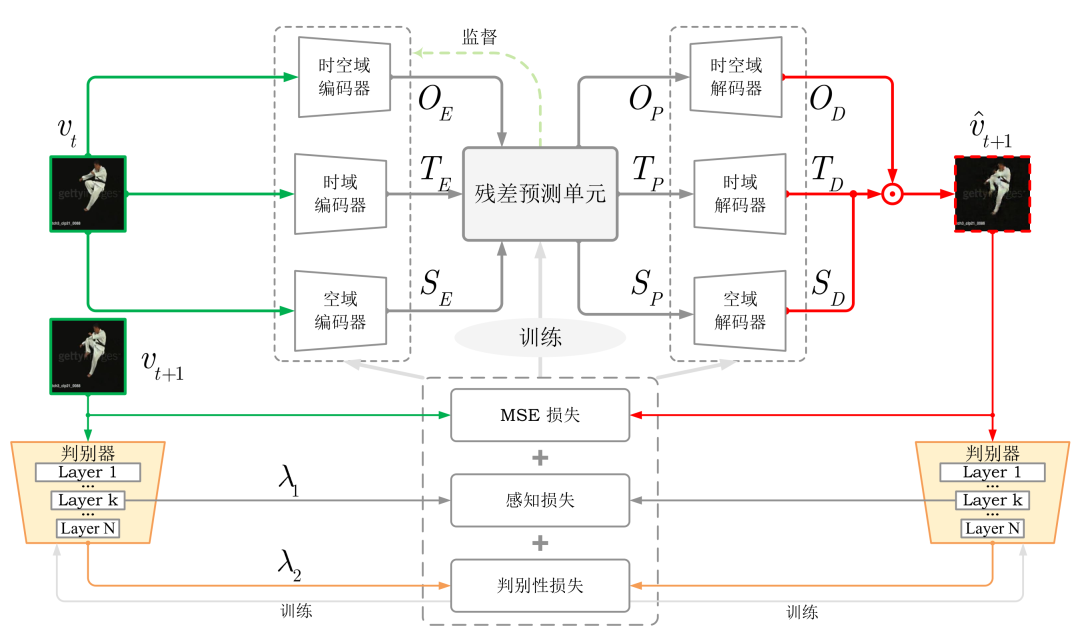 图2 时空残差预测模型整体框架
图2 时空残差预测模型整体框架
为保护高分辨率视频的高维空域信息,本文采用多个编码器在时空域上分别进行特征提取,减少信息相互干扰的同时提高信息利用率,具体特征提取过程如下所示,
经过以上方式提取的特征将会被输入到本文所提出的轻量级残差预测单元(Residual Predictive Memory, RPM)的不同模块之中,
这种信息传递形式也会对不同编码器进行监督,使它们可以提取到不同域上的特征, RPM 的详细结构将会在下文中详细介绍。经过 RPM 的时空建模,未来视频帧的低维时空特征表现为如下形式,
和时空编码过程类似,预测出的时空特征将会被独立地解码到高维空间,如下所示,
借助于传统 ST-LSTM[1]输出模块融合时空状态的过程,解码出的高维时空特征将会被融合为最终的高分辨率预测帧:
本文所提出的残差预测单元RPM的具体结构如图2所示
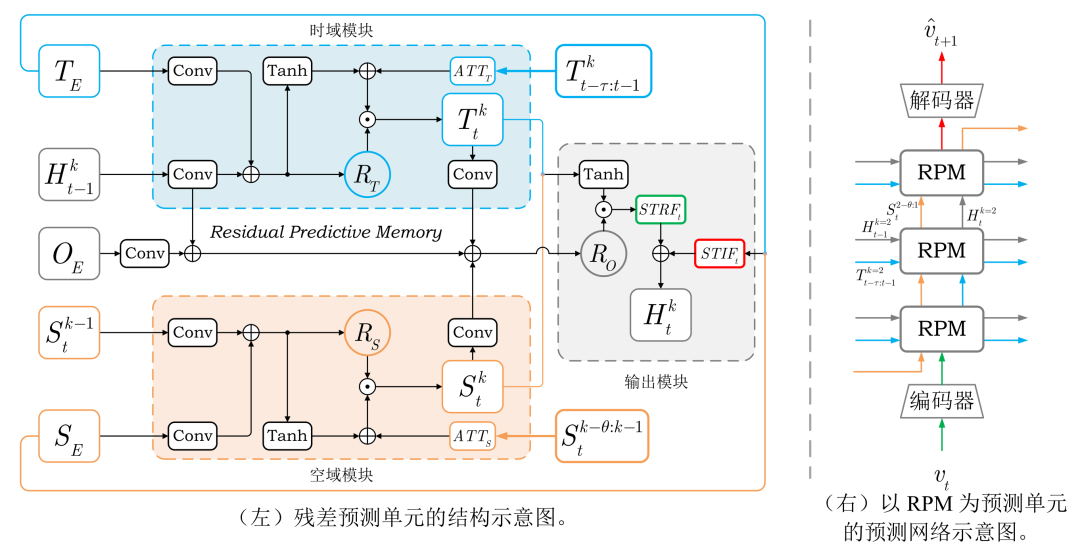 图2 时空残差预测单元(RPM)
图2 时空残差预测单元(RPM)
如上所示首先输入预测单元的输入将会通过卷积神经网络进行特征提取,如下所示,
随后RPM中的两个门结构负责建模时空残差信息,分别为时域残差门和空域残差门,
以上定义的两个残差门将会负责建模下面的时空残差信息T和S,
最终的输出状态H将由时空残差信息STRF和时空输入信息STIF共同决定,
另外在训练过程中,为了使模型可以为高分辨率视频帧生成较为真实的纹理细节,本文同时引入判别式损失和确定式损失。但是由于判别式损失和确定式损失如 MSE 等会相互影响,并会导致训练过程不稳定。
本文额外引入了一个可以进行动态学习的感知损失。由于 GAN 中的判别器可以判断生成内容的真假情况,因此本节将判别器中间层输出的特征定义为当前视频帧的感知表征,预测值和真实值的感知表征距离便是本文提出的新型感知损失:
最终总的损失函数如下所示,
实验结果
本节在三个分辨率较高的数据集上测试所提出方法的性能和可行性。第一个数据集为 UCF Sports 数据集,分辨率为720×480。第二个数据集为 Human3.6M 数据集,分辨率为1000×1000。第三个数据集为 SJTU4K 数据集,分辨率为3840×2160。
表1中统计了不同方法在 UCF Sport 数据集和 Human3.6M数据集上的客观指标 PSNR 和主观指标 LPIPS 表现情况。其中 PSNR 越高显示客观质量越好,LPIPS 约小,显示主观质量越好。可以看出所提出的方法在建模高维数据方面有着明显的优势。
表1 不同方法在 UCF Sports 数据集和 Human3.6M 数据集上的客观性能指标和主观性能指标情况。
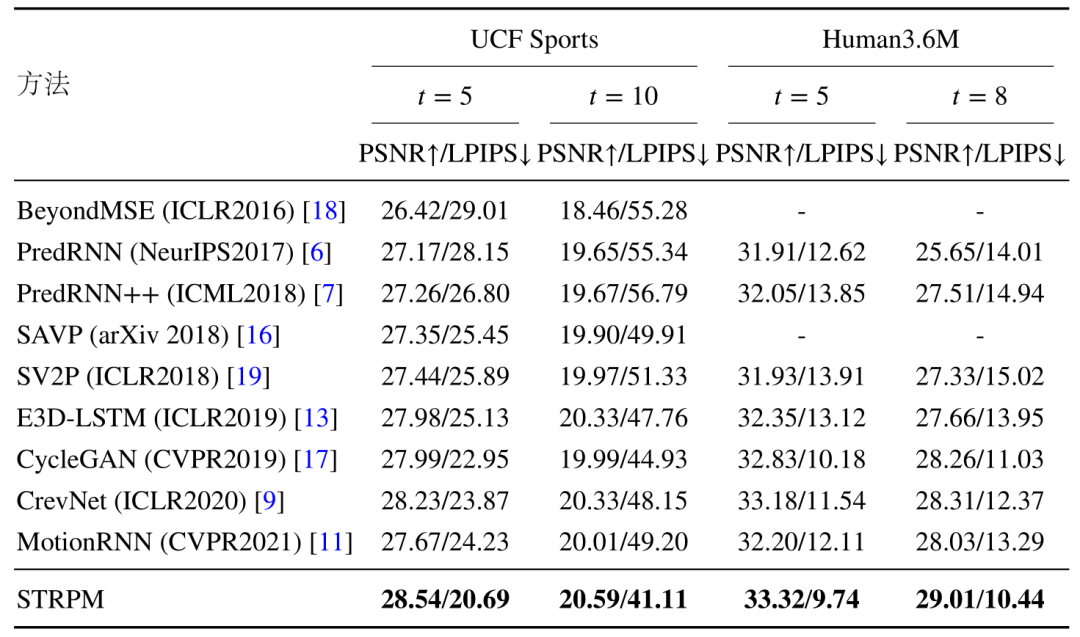
表2统计了不同参考模型的计算复杂度和参数量信息,可以看出本文所提出的 RPM 预测单元以最小的计算复杂度实现了最优的性能。同时 RPM 所特有的残差结构可以明显提高模型性能。并且时空编解码机制也可以有效保护高分辨率视频的空域信息。
表2 模型效率参数统计表。测试数据集为 Human3.6M,测试条件为 4 帧预测 4 帧。所有模型的编码器和解码器结构都相同,并且所有的预测单元隐藏通道数都为 128,预测单元数量为 16。所有模型都只使用 MSE 损失函数进行训练。
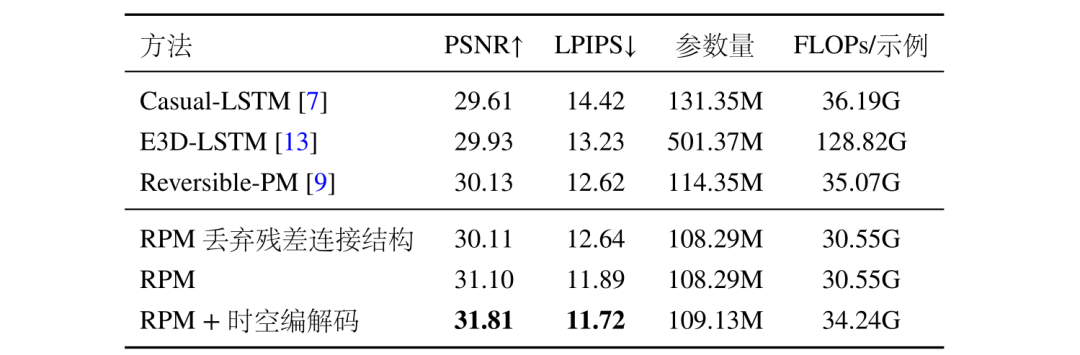
表3总结了不同方法在4K 视频预测场景上的性能指标表现和复杂度表现,可以看出本文所提出的高分辨率视频预测框架在性能和计算法复杂度上均取得了较好的表现。
表3 不同方法在 SJTU4K 数据集上的客观性能指标和主观性能指标情况
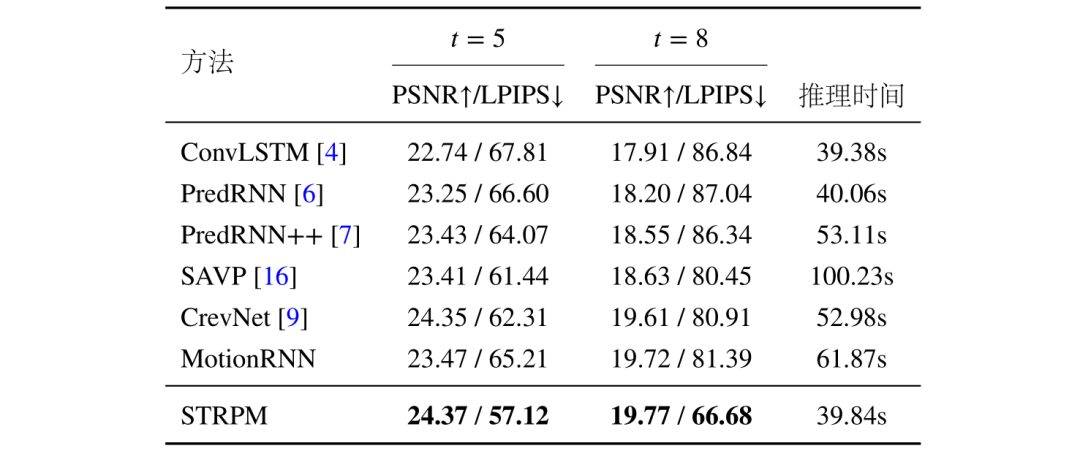
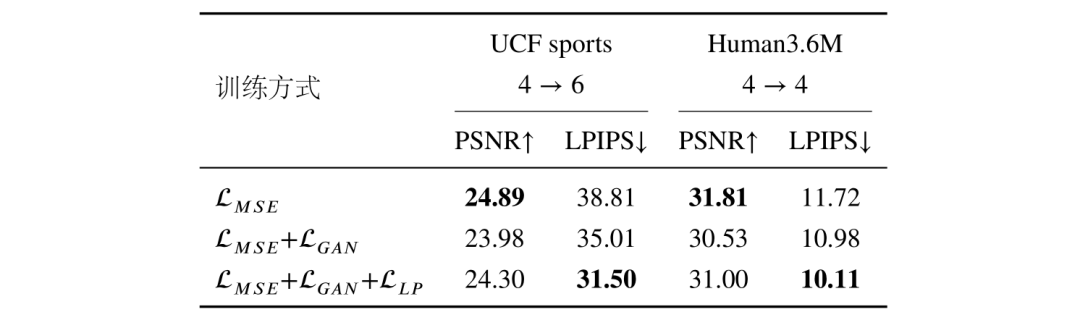
表4统计了不同训练方式对模型性能的影响,可以看出本节所提出的感知损失可以有效帮助预测算法在主观指标 LPIPS 和客观指标 MSE 之间达到一个合理的均衡。
表4 模型在不同训练方法下的性能表现
更多方法实验细节详见原论文。
参考文献
[1] Wang Y, Long M, Wang J, et al. Predrnn: Recurrent neural networks for predictive learningusing spatiotemporal lstms [C]//Advances in Neural Information Processing Systems. 2017:879-888.
[2] Yu W, Lu Y, Easterbrook S, et al. Efficient and information-preserving future frame prediction and beyond [C]//International Conference on Learning Representations. 2019.
[3] Wang Y, Jiang L, Yang M H, et al. Eidetic 3d lstm: A model for video prediction and beyond[C]//International Conference on Learning Representations. 2019.
原文链接